〇. 前言
笑死,大半个月不摸全忘了。
第三章讲的是机器语言,内容很多但难度不高,目前对于做 lab 毫无头绪所以不如把整个章节再梳理一遍。
一. 导论
对于机器代码,我们有两个十分重要的抽象:一是指令级架构,二是虚拟地址(第九章)。
利用 指令集架构,编译器可以将我们所写的C语言代码转化为计算机可以理解的机器代码。 编译器会先将其翻译为 汇编代码,我们可以利用汇编代码去理解计算机是如何执行程序的。
机器代码通常由三部分组成:
- 程序计数器:在寄存器内用
%rip表示,指向下一条指令的地址。 - 整数寄存器:16 个命名的位置,分别存储了 64 位的值(比如说 地址,整数数据)。
- 状态寄存器:保存了最近执行的算术或逻辑指令的状态信息。
机器代码对一切数据一视同仁,不区分有符号或无符号,不区分各个类型,不区分指针与函数。
二. 信息访问
1. 整数寄存器:
有几种特殊的 Registars 需要记住:
%rsp栈指针;$rdi函数调用的第一个参数;$rsi函数调用的第二个参数;%rdx函数调用的第三个参数;%rax函数的返回值;
64位的寄存器可以向下兼容。
2. 操作数指示符:
- 寄存器,直接调用即可;
- 立即数,直接由
‘$’+整数表示; - 内存引用,在寄存器外部加上括号表示。
同时,如果在括号前加个位移数 D,可以获得一个指向 距离寄存器地址偏移 D 地址的一个数。
更多地,D(Rb,Ri,S) 可以表示指向 Reg(Rb)+S*Reg(Ri)+D 地址的一个数。 当谈论 数组时,我们可以利用该方法简化表述。
3. 数据传送指令: 与
mov 可将数据从某一位置复制到另一位置;
mov 后跟着的字符代表了其操作的大小,如 movq 可以移动四字的数据。
特殊的,对于 movl,它可以生成四字节值;而且如果以寄存器作为目的时,它可以顺手将高四位设置为 0.
这貌似对于任意计算指令都适用。(自下而上兼容如是说)
- 立即数可以移动到寄存器或内存地址
,如movq $0x4 (%rax)等价于*p = 0x4; - 寄存器可以移动到寄存器或内存地址
- 内存只能移动到寄存器,内存间不能移动
而 可以利用地址表示法来计算地址,但也是一种方便的算数计算方式。
与 不同,它仅会将 计算后的内存的地址值 赋给寄存器,而非其指向。
如:
int m12(int x) { return 12*x;}
汇编语言等价为:
leaq ($rdi,$rdi,2) %rax //$rdi -> x, %rax -> return value
salq $2 $rax // %rax left_shift 2 -> %rax*4
4. 算数计算指令: 与
还有其他的,比如 imul , sal, xor 等,
sarq 代表了算术右移,shrq 代表逻辑右移。
值得注意的一点是,操作数的顺序往往与正常情况相反。只需要记住 源在前,目标地址在后 即可。
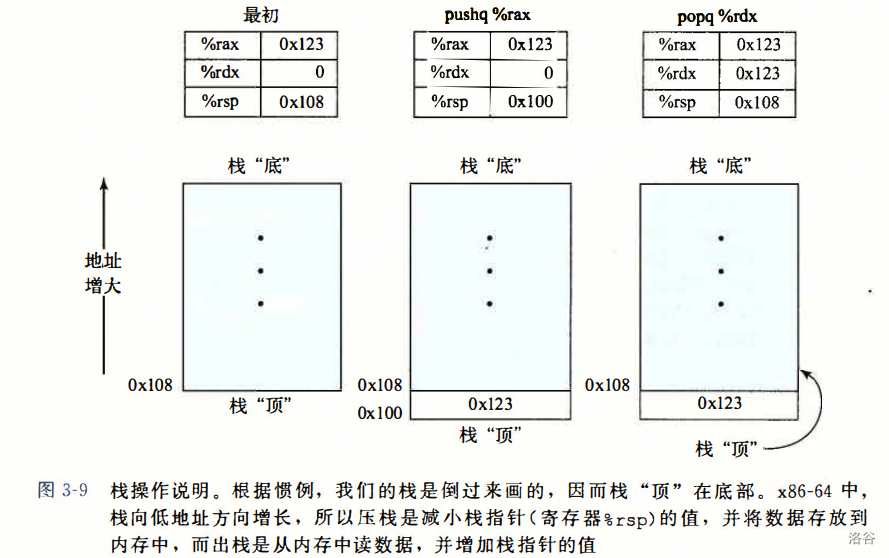
5. 压入,弹出栈数据
利用专一的 %esp 指针,我们可以自由的读取栈内某一元素的值(通过 0x4(%rsp) 的表达形式)。
每当进行 push 操作后,实际上等价于先将栈指针减 8,再将数据存储到 %rsp 所指的地址上。
pop 操作后原先地址的值其实没有改变,改不改变都无所谓了。
三. 控制
对于非线性结构,如条件、循环和分支语句,我们可以根据 数据测试 的结果来改变控制流或数据流。
其中,jump 指令可以改变机器代码指令的执行顺序,基于某种测试结果。
1. 条件码
CF: Carry Flag进位标志,判断无符号操作结果是否溢出。ZF: Zero Flag零标志,判断操作结果是否为零。SF: Signed Flag符号标志,判断操作结果是否为负。OF: Overflow Flag溢出标志,判断补码操作是否溢出(正或负)
除了 lea 指令只读取不引用,其他操作均会改变条件码。特殊地,有两个指令只会设置条件码而不改变寄存器: cmp 与 test。
cmp s1,s2除了不改变 s1, s2 的值以外与sub一样。test除了不改变 s1, s2 的值以外与and一样,常用作单独判断某一个值的各种情况(test %rax %rax)。
当访问条件码时,我们可利用 set 指令去基于条件码的组合,将某个寄存器的单个字节设置为 0 or 1 。
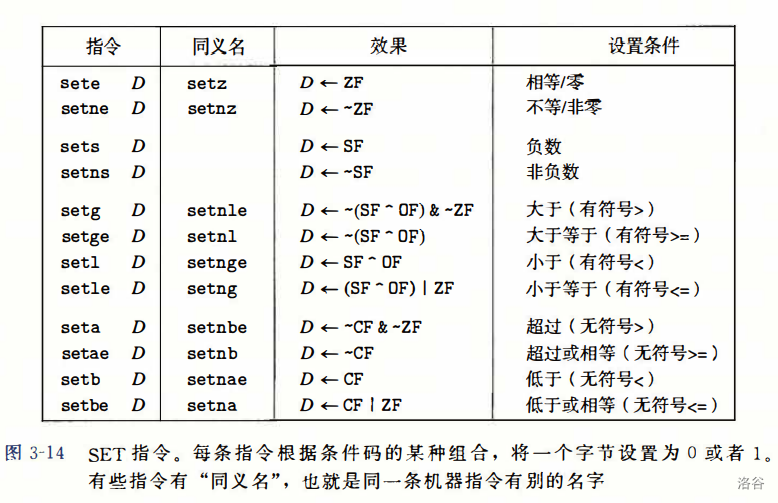
其中一些操作明显涉及到了补码的知识。如 setg 表示 结果为负数且没有溢出,或者结果为正数但溢出 时判断为大于;setl 表示若结果为负数,或结果非负但发生溢出 时判断为小于,由于结果非负时仅会发生负溢出,且溢出必不可能 a=b,故该表示法是十分正确的。
2. 跳转指令
感性理解为 goto,只不过有加了几个有条件跳转的 goto。
3. 条件语句
我试图复刻 15213 课件里面的代码,发生了很有意思的事情。
课件:

我的:
0x004016b9 <+9>: mov %edx,%eax
0x004016bb <+11>: sub %ecx,%eax
0x004016bd <+13>: mov %ecx,%ebx
0x004016bf <+15>: sub %edx,%ebx
0x004016c1 <+17>: cmp %edx,%ecx
0x004016c3 <+19>: cmovge %ebx,%eax
0x004016c6 <+22>: pop %ebx
怎么会事呢?这事实上是两种实现条件转移的途径:
- 前者是使用 控制 的条件转移,当条件满足时程序沿着某一条路径执行,条件不满足就走另一条途径;
- 后者是使用 数据 的条件转移,同时把两个结果都算出来,可行的话就用 条件传送 指令实现它。
第 4,5 章中我们会了解到,现代处理器会使用 流水线 提前处理命令从而提高性能,当遇到条件分支时他会随机决定分支,使得流水线上能充满指令。然而一旦错误就会致使严重的性能下降。
使用 条件传送 时,我们计算出两个值,最后再决定将哪个放到寄存器里面,这就防止时间的浪费。
但如果分支结构的两块都十分复杂,那编译器也怂了,会换回条件控制转移。
如:
int abs(int a,int b) //我乱写的。
{
int res;
if (a < b)
{
res = b-a;
a = b*2;
b = res - a*2;
}
else {
res = a-b;
a = a*3;
b = res - a*3;
}
return b;
}
它对应的汇编代码即为:
0x004016b0 <+0>: mov 0x4(%esp),%edx
0x004016b4 <+4>: mov 0x8(%esp),%ecx
=> 0x004016b8 <+8>: cmp %ecx,%edx
0x004016ba <+10>: jge 0x4016c6 <abs(int, int)+22>
0x004016bc <+12>: mov %ecx,%eax
0x004016be <+14>: sub %edx,%eax
0x004016c0 <+16>: shl $0x2,%ecx
0x004016c3 <+19>: sub %ecx,%eax
0x004016c5 <+21>: ret
=> 0x004016c6 <+22>: mov %edx,%eax
0x004016c8 <+24>: sub %ecx,%eax
0x004016ca <+26>: lea (%edx,%edx,2),%edx
0x004016cd <+29>: lea (%edx,%edx,2),%edx
0x004016d0 <+32>: sub %edx,%eax
0x004016d2 <+34>: ret
4. 循环结构
三种循环都有其对应的模板。
do-while循环
do {
body;
} while (test);
等价于:
LOOP:
body;
t = test;
if (t) goto LOOP;
while循环
while 循环有两种翻译方法:Jump To Middle 和 Guarded-do。
后者常出现在 -O1 优化中。
while (test) body;
等价于(Jump To Middle):
goto test;
LOOP:
body;
test:
t = test;
if (t) goto LOOP;
亦等价于(Guarded-do):
t = test;
if (!t) goto END;
LOOP:
body;
t = test;
if (t) goto LOOP;
END:
前者是先跳到末尾进行判断,再调回中间执行整体;后者进行判断后转化为do-while 循环。
for循环
for 循环的通用格式如下:
for (init; test; update) body;
可等价为:
init;
while (test)
{
body;
update;
}
之后与 while 循环等价。
然而,我们还要注意到有 continue 这么一个东西,会打乱我们的逻辑。
举个小栗子,求 1~10 内所有偶数的乘积:
int frac(int a)
{
int res=1;
for (int i=1;i<=10;i++) {
if (i&1) continue;
res *= i;
}
return res;
}
对应的汇编程序为:
<+0>: push %ebx // %ebx -> a
<+1>: mov $0x1,%edx // %edx -> i
<+6>: mov $0x1,%eax // %eax -> res
<+11>: jmp <abs(int)+31> //jump to middle
<+13>: mov %edx,%ebx //make a backup of %edx.
<+15>: and $0x1,%ebx //do a test
<+18>: mov %eax,%ecx //make a backup of %eax
<+20>: imul %edx,%ecx //still do a mul
<+23>: test %ebx,%ebx // if test,
<+25>: cmove %ecx,%eax // cover %eax with %ecx
<+28>: add $0x1,%edx // update
<+31>: cmp $0xa,%edx // test the loop
<+34>: jle <abs(int)+13>
<+36>: pop %ebx
<+37>: ret
由汇编代码可见,编译器根本不管 continue 鸟事,依旧进行了之后的操作,只不过是在一个 备份 上进行;
到最后判断一下,如果不满足 continue 的条件,才会放心把更新后的答案放回去。
5. Switch 语句
你以为 Switch 语句只是一堆 if 叠一起,其实完全不同。
多重分支 的索引开关可以由 Switch 语句完成,其中 跳转表 的使用使这种数据结构更加高效。
对于 Switch 语句内的每一个分支,都会被视作一个 代码块,而代码块的开头会有那么一个地址,存储在跳转表中。
对于所有 Case 里的最大值和最小值,跳转表会对其中所有值都制到表里面(加上某个 bias),到时候跳转只需跳到对应的地址即可。具体的,可以这样操作: jmp *.L4(,$rdi,8)
如果最小值和最大值过大,他实际上会执行一个二分的过程,将跳转表转化成一个跳转树,防止跳表时爆炸到 O(n)。又或者, Switch 语句会直接退化(?)成 if-else 语句。
四. 过程
编译器在编译程序时,会尽量减小空间开销。
1. 运行时栈 与 栈帧
栈并非什么特殊区域,而不过是内存中的一段连续区间。栈指针 $rsp 始终指向栈顶,当执行入栈操作 pushq ,则将栈指针递减(减 8);当执行出站操作 popq,则将栈指针递增(加 8)。
当所需存储空间 超过寄存器的上限 后,编译器会在栈上为其分配空间块用于存储更多数据。这个部分称作过程的 栈帧。比方说当过程 P 调用过程 Q 时,会先将 返回地址 压入栈( %rsp,便于 Q 运行结束后能回到原先的位置,此时的返回地址也属于 P 的栈帧),为 Q 过程提前分配一定的内存空间,再将 PC(%rip) 设置为 Q 的起始地址即可。
当我们对于 Q 所需要的内存空间不清楚时,我们往往还会引入 基指针 的概念,指向上次调用的栈顶地址。
上述过程即是通过 callq 指令来 控制 的;
而 ret 指令会弹出此时栈顶的地址,并将 PC 设置为该地址,这样便可回到初始的位置,此时 Q 过程内的一切东西都会被释放(deallocated)。
2. 数据传送 与 局部存储
如果某个函数的参数量大于 6,超出 6 的部分需要栈来传递;如果超出 6 的部分十分巨大(比如 ),你的运行栈也存储不下,那就 爆栈 了。
特别地,寄存器中的值是所有过程会共享的资源,为了保证当前的寄存器值不会因为调用了某些过程而发生不被期望的改变,我们应当做一些约定:当 **调用者(caller)**调用了被调用者(callee),callee 不会覆盖caller 会使用到的寄存器值。
Caller Saved: Caller saves temporary values in its frame before the call.
Callee Saved: Callee saves temporary values in its frame before using; Callee restores them before returning.
具体来讲,寄存器 %rbx, %rbp, %r12~%r15 被划分为被调用者保存器。过程开始调用时会将其压入栈内,如果遇到了调用者保存的情况,则将其赋值到 %rbx 头上;而且当该过程结束调用后,%rbx 也会恢复原来的值。
3. 递归
把之前那个求阶乘的代码写成递归的形式:
int call(int x) {
int ret;
if (x <= 1) ret = 1;
else
ret = x * call(x - 1);
return ret;
}
则对应的汇编代码为:
0x00401530 <+0>: push %ebx //作Caller saved
0x00401531 <+1>: sub $0x18,%esp //预分配内存
0x00401534 <+4>: mov %edi,%ebx //备份
=> 0x00401538 <+8>: cmp $0x1,%ebx //条件传送
0x0040153b <+11>: jg 0x401547 <call(int)+23>
0x0040153d <+13>: mov $0x1,%eax
0x00401542 <+18>: add $0x18,%esp //释放内存
0x00401545 <+21>: pop %ebx //恢复保存器
0x00401546 <+22>: ret
0x00401547 <+23>: lea -0x1(%ebx),%eax //计算 n - 1
0x0040154a <+26>: mov %eax,%edi
0x0040154d <+29>: call 0x401530 <call(int)> //递归
0x00401552 <+34>: imul %ebx,%eax
0x00401555 <+37>: jmp 0x401542 <call(int)+18>
即,递归没啥特别的,仍属于同一框架下。
五. 数据表示
对于给定的一个数组,则会分配一定的内存用作存储这些数据,且分配内存的大小即是 数据类型的大小 乘以 元素数。
编译器通常会根据数组的 起始地址 加上某一 偏移量,得到某一特定元素。
对于如下函数:
int get(int *a, int x) { return a[x]; }
有如下函数:
=> 0x00401530 <+0>: mov 0x4(%esp),%eax
0x00401534 <+4>: mov 0x8(%esp),%edx
0x00401538 <+8>: mov (%eax,%edx,4),%eax
0x0040153b <+11>:ret
由于 int 是四字节,故 %eax + 4 * %edx 即为 a[x] 所在地址。
1. 数组 与 指针.
我们都知道,数组可以视作指向首项的指针。 整型变量会分配 4 字节,而整型变量的指针会分配 8 字节。
那么对于两者混用的情况,以下是我们要做出区分的:

C -> 能否过编; N -> 是否引用空指针; S -> 它的大小;
对于第三种情况,int (*A)[3], 这指的是 指针A 指向 一个大小为 3 的数组,但对于该数组我们并没有定义,故 *(*A[3]) 可能会调用空指针。
对于第四种情况,首先 括号 的优先级要大于 星号, which means 它与第二种情况是等价的。同样的,我们没有定义其指向的整型地址,故会发生空指针调用。
2. 二维数组
我们可以将 a[3][5] 视作 (a[3])[5],即一个三个元素的数组,每个元素是一个五元素的数组。
二维数组 A[R][C] 在内存中是这样排列的,我们会注意到他会先存储完一整行再存下一行,我们称其为 行优先原则:
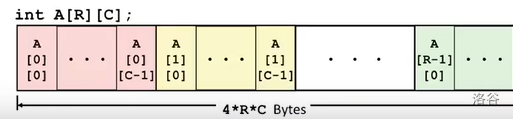
因此,当我们调用特定元素 A[i][j] ,只需取 A + (i*C*4) + (j*4) 即可。
3. 结构体
一个结构体仍代表着一段连续的内存区域,且存放元素的地址会严格按照你的定义,依次存储。但计算机系统对合法地址做出了限制,使其某类型对象的地址必须是 K (K=2, 4, 8) 的倍数,我们称其为 对齐。
因此,如果结构体定义的烂,可能会出现如图多占用内存的问题:

对此,我们只需贪心地将字节数大的排在前面,就可以最小化浪费。
六. 浮点代码
-
在 AVX 浮点体系结构下,有 16 个为浮点数准备的寄存器,他们分别为
%xmm0 ~ %xmm15; -
而它的指令集,我确实没看懂:
vcvttsdsiq,指用截断的方法将单精度数转化为四字整数,大概是这种画风的。